212803/06
212803/06

“苹果砍掉造车项目,核心团队转向人工智能。”
这是上周车圈,乃至整个科技圈最炸裂的新闻。
马斯克表示“salute”,贾跃亭觉得“是个大错误”,李想认为“完全正确”,雷军则深表“震惊”。
不过,就在大家都在为苹果砍掉造车项目感到震惊时,或许更应该被关注的是后者。
作为拥有万亿市值的全球科技巨头,苹果一直都不是新技术的创造者,但却往往能成为新规则的制定者,这就是过往这半个世纪苹果展现出的魔力。
这次,“后知后觉”的苹果,也要开始重金投入生成式AI了。
实际上,在经历了这几年的狂热后,生成式AI正在撬动整个科技产业的底层逻辑,例如芯片。
倘若生成式AI是未来的必然,是否应该为全新的计算模式设计一颗配套芯片?
于是,在谷歌主导了TPU项目研发的Jonathon Ross,于2016年从谷歌离职创业,开始专心做这样一颗AI芯片。
八年后,一次偶然的机会,这颗芯片得到了全世界的关注。
01
谷歌造芯计划
谈起AI,曾经的谷歌,是商业帝国中当之无愧的霸主。
这是因为谷歌起家的主业——搜索业务,对人工智能技术一直有着很高的需求。
从这一点上来看,作为中国搜索领域*霸主的百度,也或多或少借鉴了谷歌的发展经验,不仅在2017年的首届AI开发者大会上喊出“All in AI”,还从AI芯片、AI算法、AI硬件,一路干到了大模型。
近几年,百度还将一手培养起来的NLP专家王海峰,提拔到了百度CTO的位置上。
谷歌是在2016年由刚刚上任CEO不久的Sundar Pichai提出的“AI First”战略。
在此之前,谷歌虽然奉行的是“Mobile First”战略,但由于搜索、云计算,以及一些创新业务对AI的迫切需求,谷歌一直在向AI领域追加投入。
甚至在2014年砸了6亿美元,收购了一家名为DeepMind的英国人工智能创业团队。
值得注意的是,这个团队在2010年成立时,创始人Demis Hassabis提出的*目标,就是要(AGI)。
而谷歌动为人工智能,或者说当时很时髦的机器学习算法研发一颗芯片的想法其实要更早,可以追溯到2006年。
起因依然是谷歌核心业务对AI算法的强需求,当然还有另一个重要原因是,云计算技术这一年在谷歌内部业务上开始被使用。
而究其根源,实际上是谷歌大量互联网业务对“日益增长的服务器算力资源需求”与“服务器算力资源无法满足谷歌业务需求”之间的矛盾。
怎么解决这一矛盾?
好的算法谷歌自然不缺,毕竟有那么多优秀的软件工程师,然而,要想解决上面这一问题,*的方法还是软硬一体,也就是苹果那套玩法。
既然如此,那就别纠结了,开干吧。
谷歌是在2014年完成这颗芯片研发的,并为这颗基于ASIC架构开发的AI加速专用处理器取了一个还不错的名字——TPU(Tensor Processing Unit),张量处理器。
这颗芯片在研发成功后,直接被应用到了谷歌的数据中心中,用上TPU的谷歌数据中心被Sundar Pichai称为“AI First数据中心”。
这样的数据中心,具体有怎样的AI表现呢?
以前文提到被谷歌收购的DeepMind研发出曾轰动一时的AlphaGo为例:
2015年10月,AlphaGo击败欧洲围棋冠军,当时背后支撑AlphaGo的算力是由1202块CPU+176块GPU提供;
2016年3月,AlphaGo击败世界围棋冠军李世石,当时背后支撑AlphaGo的算力则是由50块TPU提供;
2017年5月,AlphaGo击败世界围棋冠军柯洁,当时背后支撑AlphaGo的算力已经是由4块TPU提供。
由此可见,TPU对于机器学习算法,尤其是机器学习中的推理有多重要。
Jonathon Ross,正是谷歌TPU项目的主要设计者之一。
不过,就在谷歌TPU研发完成后,Jonathon Ross也从谷歌离职开始创业,并在投资人的帮助下,将谷歌TPU初创团队10人中的8人拉到了他的新团队中。
这位眼光毒辣的投资人是Chamath Palihapitiya。
02
八位“叛逃者”
Palihapitiya被视为是硅谷最耿直的年轻一代投资人,他是在2014年年底一次会议上听说谷歌在搞TPU。
当时他还在想,谷歌难不成要和英特尔、高通、英伟达这样的芯片巨头竞争?
当时离谷歌TPU正式对外发布还有两年,市面上只有传言,没有实证。
在几经调查后,Palihapitiya在一定程度上验证了自己的猜想,并最终有了另外一个大胆的想法——找到这个团队的核心成员,搞一个AI芯片的创业项目。
作为一位颇具资源的投资人,他最擅长的就是找人,不过,为了找出谷歌TPU核心团队人员名单,他还是花了将近一年半的时间。
之后,就有了Jonathon Ross在内的谷歌TPU团队8位核心员工的离职组建新团队。
新团队名为Groq。
虽然顶着“谷歌TPU核心团队”的光环,但在Groq最初成立的几年里,团队一直比较低调,也没有弄出像DeepMind团队AlphaGo这样的大动静。
媒体上对它的报道也都浮于表象,只是说它筹集了1000万美元,在Delaware州注册了公司,好像是在搞AI芯片。
CNBC在2017年找到Palihapitiya求证此事时,Palihapitiya也只是用“现在谈具体细节还为时尚早”搪塞了过去。
不过,他还是确认了这个团队确实在研发AI芯片,一种被称作“下一代芯片”,“可以让 Facebook、亚马逊、特斯拉等公司利用机器学习做一些以前做不到的事情的芯片。”
这颗芯片真正炸场是在全球经历了百模大战后,就在前不久谷歌和OpenAI掰手腕时,每秒能输出超500个token的Groq意外走红。

从响应速度上来看,Groq比OpenAI的GPT-4和谷歌的Gemini快了10-18倍。
由于Groq对外提供100万个token的免费试用,看了Groq相关新闻后,锌产业最近也在Groq官网上试用了它的服务,响应速度确实没话说,几乎就是整段、整页地往外蹦。
不过,对话内容的质量还是不如GPT-4和Gemini。

Groq响应速度之所以这么快,正是因为使用了自研的GroqChip,这也是一个名为LPU的新型处理器。
其实GroqChip实现的理论基础,Groq团队在2020年发表的一篇论文中有提到,即TSP(Tensor Streaming Processor)架构。
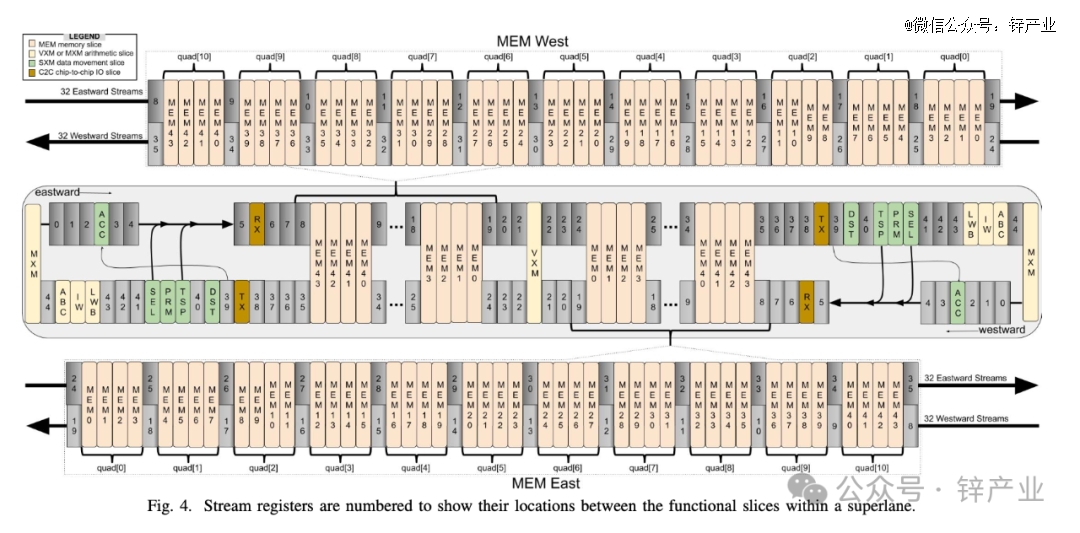
Groq在2022年的另一篇论文中又着重介绍称,这种架构更适用于大规模机器学习。
彼时,百模大战还未正式开启,Jonathon Ross很可能也没想过Groq会在两年后因为大模型(而不是机器学习)火遍全球。
不过,这不是关键。
关键在于,Groq不是一个计算密集型处理器,而是一个访存密集型处理器。
03
芯片战前传
在讲计算密集型处理器与访存密集型处理器有何不同之前,我们先来聊一聊另一个古老的故事。
2023年10月,在夏威夷的骁龙峰会上,手机处理器巨头高通在发布会上一反常态,花大篇幅讲了一颗PC芯片(X Elite)的故事。
这不是高通*次向PC芯片大佬英特尔发起挑战,虽然前几次战况惨烈,高通都未能如愿在主流PC市场打起多少水花。
但这次有了苹果这个搅局者,让高通有了更多信心。
实际上,作为芯片领域霸主,英特尔的隐患自其出生以来,就一直存在。
这和英特尔当时的一个选择有关。
1968年7月,硅谷“八叛徒”中的两位——Robert Noyce和Gordon Moore从仙童半导体“叛逃”,创立了英特尔公司,并开始开展他们的芯片设计宏图大业。
英特尔初入市场时,复杂指令集(CISC)是当时设计芯片*主流范式,没得选的英特尔就开始使用复杂指令集设计芯片。
大约是在英特尔成立十年后,一种名为精简指令集(RISC)被IBM研究中心John Cocke提出,后经时任斯坦福大学校长的John Hennessy写进了美国大学的计算机课本。
RISC一经提出,学术界一致认为RISC处理器要好于CISC处理器。
RISC处理器不仅解决了CISC处理器设计复杂,实现同样性能需要更高集成度的问题,还一定程度上避免了由此带来的功耗问题。
从技术实现上来看,也确实如此。
彼时,基于RISC处理器设计的工作站,运行速度普遍快于基于CISC处理器设计的工作站,而且是肉眼可见的差距。
然而,当时英特尔在CISC处理器上已经有了十年的技术积累,转向RISC处理器就意味着要放弃这样的技术积累和好不容易构建起的市场优势。
几经斟酌后,英特尔选择了“逆技术潮流而行”,依然采用CISC设计处理器,这样也保持了前向兼容。
英特尔之所以敢这么做,很大一个原因是当时RISC阵营没有出现像ARM这样强劲的对手(ARM是1990年成立的)。
英特尔最后也确实赌赢了。
前谷歌高级研究员吴军曾指出,英特尔之所以能赢得这场战争有几个原因:
*,英特尔坚持自己系列产品的兼容性,积累了软件生态;
第二,英特尔利用规模优势,大强度投入研发,英特尔每款处理器的研发投入都高于当时市面上任意一款RISC处理器的投入;
第三,英特尔曾研发过两款RISC处理器,但用户依然选择了英特尔的CISC处理器,事实证明,用户对兼容性比对性能要求更高;
第四,RISC处理器阵营当时没有像样的对手。
总结而言,“英特尔不是靠技术,而是靠市场打赢了这场战争。”
然而,在PC市场败北,并没有影响RISC处理器的崛起,后来高通和ARM的出现,以及移动互联网的来临,让基于ARM架构的RISC处理器最终成了智能手机的核心。
高通在智能手机市场一骑绝尘后,也开始试探性地进攻PC市场,例如2018年推出骁龙8cx系列处理器,2019年推出骁龙7c、8c两款处理器。
因为本质上,基于ARM架构的芯片确实有机会成为PC处理器。
不过,在和英特尔几番交手后,高通最终没讨到什么好处,相关芯片后来也就不了了之。
然而,令英特尔没有想到的是,2020年11月,苹果基于ARM架构的M1芯片一经发布,彻底闯入了英特尔严防死守的腹地。
尤其是随着苹果Apple Silicon战略的持续推进,苹果在这一年后,逐渐为自家PC换上了自己的M系列芯片,这意味着全球至少有近10%的PC,将迈入迟来的RISC时代。
正因有了苹果的胜利,高通才借着AI PC的新窗口期,重新打起了自己的小算盘。
也是在这时,在这个AGI新时代,芯片产业还有一个更大的潜在变量也在酝酿中。
04
“噩梦”的开始
什么是计算密集型?
计算密集型是指,算法模型的计算密度较大,算法模型访存少而计算量大,性能受到处理器*计算峰值限制的计算类型。
什么是访存密集型?
访存密集型是指,算法模型的计算密度较小,算法模型访存多而计算量少,性能受到处理器内存带宽限制的计算类型。
由于网络、硬件等在过去40年里一直保持着超高速发展,算力一直处于供不应求状态,计算密集型处理器也就成了主流。
然而,大模型的出现,改变了这一现状。
在中,我们提到过:
如今的大模型追根溯源都是基于Transformer架构,作为自回归模型,基于Transformer的AI模型生成每一个新token,都需要将所有输入过的token计算一遍。
为了避免重复计算,在实际应用时,AI模型会将实际计算过的数据预存下来,这就导致这类模型对访存的需求要求普遍会很高。
这就导致了现在基于传统架构的计算密集型AI芯片难以满足这样的需求。
GroqChip,正是一款访存密集型处理器。
Groq团队解决当下大模型普遍遇到的“性能受到处理器内存带宽限制”问题的方法,是换用低带宽存储器SRAM。
相较于GPU使用的高带宽存储器HBM,SRAM的运行速度至少要快20倍,从而大大提高了访存带宽。
这就是为什么Groq每秒能输出超500个token的原因。
然而,由于GroqChip采用的SRAM带宽只有230MB,实际上相当于是在用空间换时间。
前阿里技术副总裁贾扬清就曾指出,Groq在运行Llama-2 70B模型时,需要305张Groq卡才足够,而用H100则只需要8张卡。从目前的价格来看,这意味着在同等吞吐量下,Groq的硬件成本是H100的40倍,能耗成本是10倍。
不过,可以看到的是,Groq只是在百模大战正酣、AGI被提上日程的现在一次大胆的尝试。
也可以说,Groq是芯片产业这场变革“噩梦”的开始。
接下来,将会有更多专为大模型设计的访存密集型芯片出现。
不知道芯片巨头们,准备好了吗?