81601/01
81601/01

12月26日消息,国产大模型DeepSeek推出DeepSeek-V3,一个强大的混合专家(Mixture-of-Experts, MoE)语言模型。主要的技术迭代是671B的MoE,37B的激活参数,在14.8万亿个高质量token上进行了预训练。
AI圈表示,“圣诞节真的来了”。

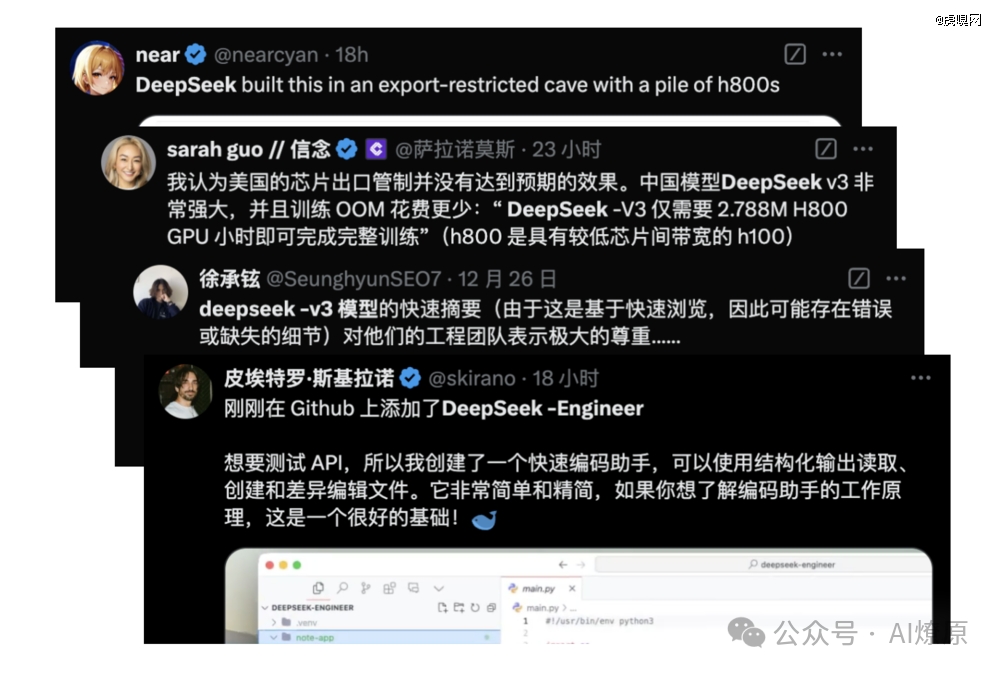
翻译翻译,首先,从训练时间看,正如DeepSeek在发布报告中指出的那样,“尽管其表现出色,DeepSeek-V3的完整训练仅需2.788M H800 GPU小时。”
打个比方,如果对标Llama 3 系列模型,其计算预算为 3930 万 H100 GPU Hours——大约可以训练 DeepSeek-V3 十五次。
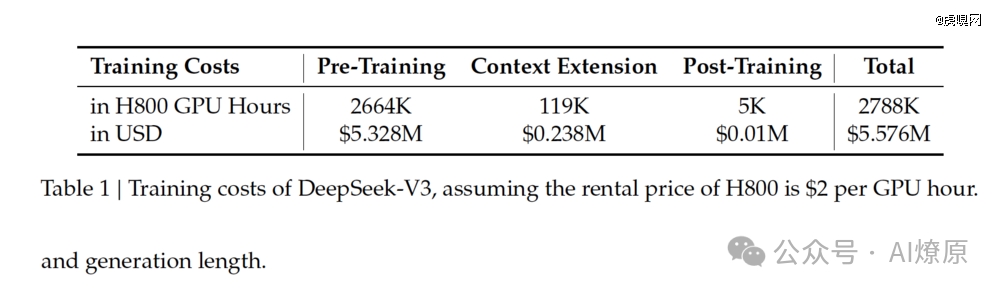
从成本上看,如果我们假设 H800 GPU 的租金为每 GPU 小时 2 美元,DeepSeek-V3 的总训练成本仅为 557.6万美元。
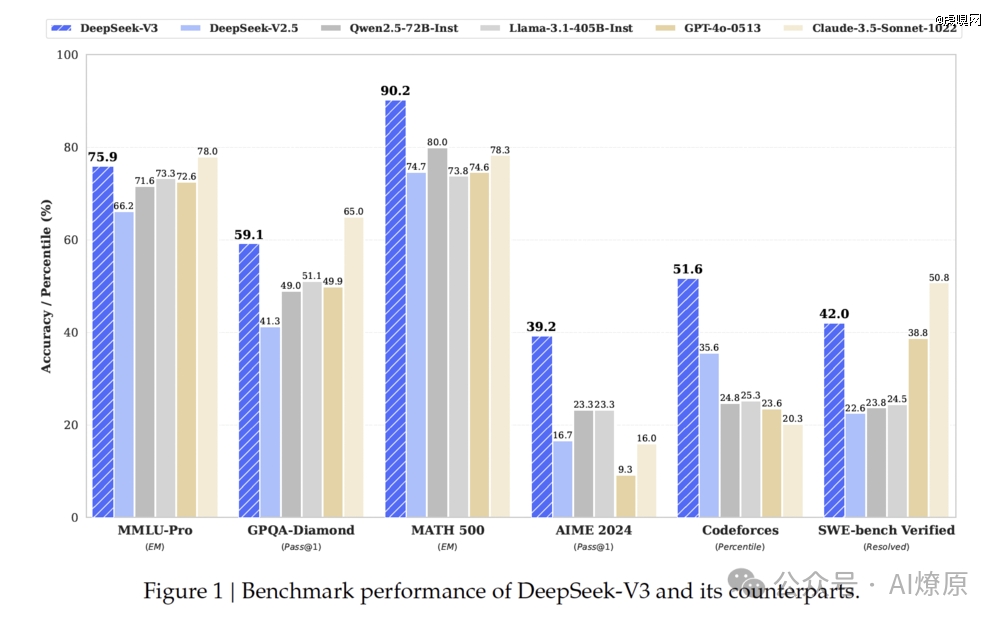
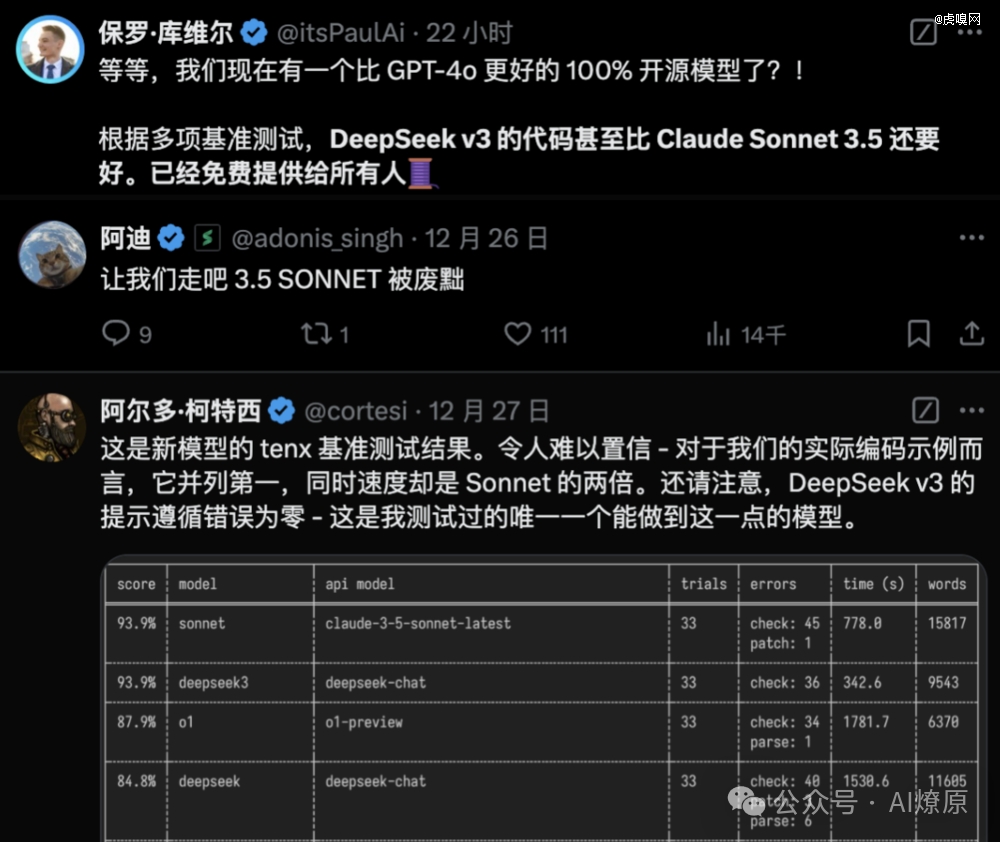
不仅如此,在最新发布的技术报告里,经过与DeepSeek-V2.5、Qwen2.5-72B-Inst、Llama-3.1-405B-Inst、GPT-4o-0513和Claude-3.5-Sonnet-1022几个模型的跑分, DeepSeek-V3 在多个性能基准测试中表现出色。在MATH500、AIME2024和Codeforces三个维度更是遥遥*,数学和编程能力极强,一度超过 GPT-4o 和 Claude 3.5 Sonnet 这两大*的闭源模型。虽然在某些语言理解和软件工程任务中稍有逊色,但也是TOP2尖子选手。
DeepSeek自言,这得益于采用了Multi-head Latent Attention (MLA)和DeepSeek MoE架构,实现了高效的推理和经济高效的训练。又引入了辅助损失自由负载平衡策略和多token预测训练目标,提升了模型性能。同时,在14.8万亿个高质量token上进行了预训练时,通过监督微调和强化学习阶段充分挖掘了其潜力。
综合评估显示,DeepSeek-V3优于其他开源模型,性能接近*的闭源模型。并且,训练过程非常稳定,没有遇到不可恢复的损失峰值或回滚。相比之下,在同一天,ChatGPT再次宕机,修复时间尚未确定。
meta AI 研究科学家田渊栋在X上对 DeepSeek-V3 “极有限的预算”和“强劲的表现”深感惊喜。
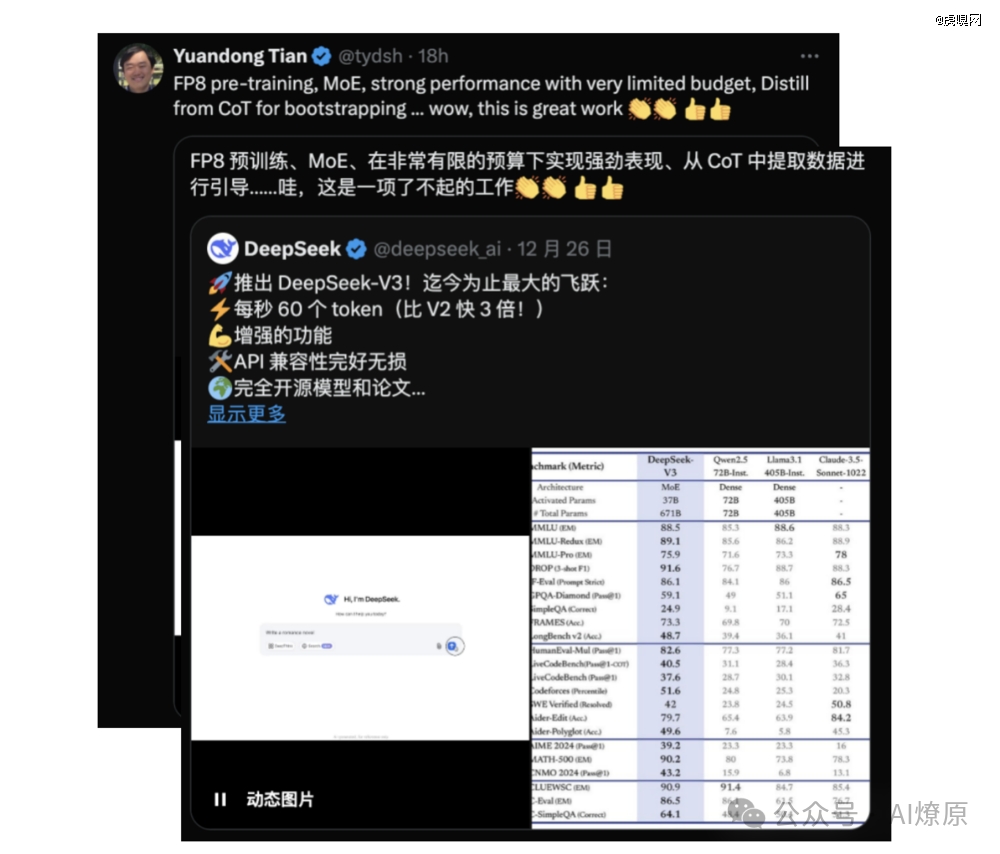
曾为 Glean 和 Google Search 的创始团队成员的 VC Deedy更是将DeepSeek-V3赞为“世界上*的开源大模型”。

DeepSeek-V3的基础模型以英语和中文为主的多语言语料库上进行预训练,因此主要在一系列以英语和中文为主的基准测试上评估其性能,同时也在一个多语言基准测试上进行评估。而基于其内部集成的HAI-LLM框架,具体跑分如下:

如上可以看到 V3 在英语、编程、数学、中文、多语言几个维度的表现。
英语(English):DeepSeek-V3 base 在大多数测试中表现*,例如在 BBH(EM)、MMLU(EM)、MMLU-Redux(EM)、DROP(F1)、ARC-Easy(EM)、ARC-Challenge(EM)、HellaSwag(EM)、PIQA(EM)、WinoGrande(EM)、TriviaQA(EM) 和 AGIeval(EM) 等测试中。在 Pile-test(BPB) 基准测试中,DeepSeek-V3 base 的得分为 0.548,也略高于其他模型。
代码(Code):DeepSeek-V3 base 在 Humaneval(Pass@1)、MBPP(Pass@1)、LiveCodeBench-base(Pass@1)、CRUXeval-I(EM) 和 CRUXeval-O(EM) 等测试中表现突出。
数学(Math):DeepSeek-V3 base 在 GSM8K(EM)、MATH(EM)、MGSM(EM) 和 CMath(EM) 等测试中表现优异。
中文(Chinese):DeepSeek-V3 base 在 CLUEWSC(EM)、C-eval(EM)、CMMLU(EM)、CMRC(EM)、C3(EM) 和 CCPM(EM) 等测试中表现良好。
多语言(Multilingual):DeepSeek-V3 base 在 MMMLU-non-English(EM) 测试中表现*。
由于DeepSeek“大方”开源,Open AI水灵灵地被网友cue进行横向对比,有一种被push的支配感。
不少玩家还在X上分享了自己的使用体验,认为DeepSeek-V3 很“聪明”,并对Deepseek团队表示极大的尊重。
DeepSeek 是一家创新型科技公司,长久以来专注于开发先进的大语言模型(LLM)和相关技术,由知名私募巨头幻方量化孕育而生,作为大厂外*一家储备万张 A100 芯片的公司,幻方量化为DeepSeek的技术研发提供了强大的硬件支持。
早在通过开源大模型如 DeepSeek Coder 等,DeepSeek 就展示了在人工智能技术领域的实力。DeepSeek V2 模型的发布,更是提供了一种史无前例的性价比,推动了中国大模型价格战的发展,并因其创新的 MLA 架构和 DeepSeekMoESparse 结构而受到业界的广泛关注。
DeepSeek 被硅谷誉为“来自东方的神秘力量”,其 V2 模型论文在当时即被认为可能是今年*的一篇。半年后,DeepSeek 带着 V3 再次登场,用行动说明,中国大模型创业者,也可以加入到这场全球技术创新的 AI 竞赛中。