230708/28
230708/28

什么是顶流?
AI大神李沐回母校做演讲,直接让上交大变成了大型追星现场——
现场可谓是人人从从众众,先来感受一下这个feel:
正式演讲前的场外已经是排起了大长龙,现场更是座无虚席。
即便是演讲结束,李沐老师也是被热情的上交大学子围得里三层外三层:

许多学生更是把经典的《动手学深度学习》这本书拿了过来让李沐老师签名:

如此场景,甚至上交大计算机科学与工程系教授俞勇都在朋友圈发出了这样的感慨:
*次亲眼看到追“星”的盛况。

△图源:俞勇教授朋友圈,已授权
对此,李沐老师也回应俞勇老师:
母校老师同学太热情了。

而李沐老师此次回母校的演讲,归结两个关键词,就是LLM趋势和个人职业选择。
△图源:小红书用户“昭曦”
尤其是正值李沐老师创业一年半(BosonAI)之际,他在现场基于自己的经历,总结了三个不同阶段中“每天在想的基本目标”:
大公司:你要想如何升职加薪
博士:你要想如何毕业
创业:你要想如何“退出”(要么上市,要么卖掉)

△图源:B站用户“Kimoyee”
金句之多,内容之精彩,引得在场师生掌声、笑声,声声不断。
那么李沐老师具体都讲了什么?我们继续往下看。
(PS:完整演讲视频见文末)
谈LLM趋势
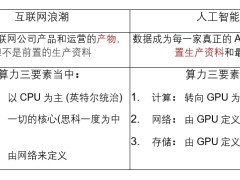
首先对于LLM的整体构成,李沐认为主要分为三大方面,分别是数据、算力和算法。

而整个LLM的过程非常像炼丹,“数据”就是找材料的环节。
就好比小说里很多主角去深山里找材料一样,搞数据是个很难的过程,是个体力活。
之后的“算力”就是炼“数据”,火量大一点、设备先进一点,能炼出来的东西就越好。
至于“算法”就相当于丹方,但这点与小说是不同的,因为它每年都在快速进步、变化,并且对细节的把控显得格外重要。
对于LLM与上一次深度学习较大的区别,李沐认为:
之前的深度学习“炼丹”是比较稳定的。
但现在LLM“炼丹”,(开发者或用户)是希望有灵魂在里面的,它能够解决很多问题。
接下来,李沐便针对上述的三大方面进行了详细的讲解。

在LLM硬件方面,李沐认为最难且最重要的是带宽(bandwidth)。
这是因为现在大模型的训练很难通过一个机器来搞定,而要做分布式,那么瓶颈就会出现在带宽上了。
毕竟现在基本上都会是多个服务器机架甚至是集群,即便两个机架间隔1米,但由此带来的哪怕几纳秒的延迟也是不能忍的。
带宽之后,LLM硬件难点便是内存(Memory)。
大模型在训练过程中,是把超大的数据压缩到了一起,使得模型的体量动辄便是几百个G,运行时的中间变量也会变得很大,因此需要很大的内存:
在未来,很有可能一个200G内存的芯片是走不动的。
这就意味着我们的模型大小一定程度上会被受限在某个尺寸;内存不够,模型就大不了。
在带宽、内存之后,便来到了算力(Compute),对此,李沐认为:
摩尔定律依旧有效。

而模型到了一定尺寸之后,资源(Resources)又成了问题,也就是供电。
李沐基于自身经验分享到,发现自己造一个电厂,比付电费的成本要低。
至于价格,当算力翻倍的时候,价格目前不一定会保持不变,可能是1.4倍的价格;但当市场竞争足够,长期来看可以做到价格不变。
至于芯片的替代品(Alternatives),李沐认为谷歌的TPU、英特尔的Habana、AMD和Azure的芯片在做推理时是OK的;但训练方面,可能还需要几年的时间。
李沐在此做了个小总结:
模型训练每年会以2倍的速度变得更便宜、更快、更大。
今年训练的大模型,到明年的价值就会减半。

在模型方面,李沐从语言(Language)、语音(Voice)、音乐(Music)、图像(Image)和视频(Video)等不同模态方面做了介绍,并认为多模态是当下的一个趋势。
李沐还给目前不同模态的现状打了个分:
语言模型:80-85分左右,目前是gets good的状态。
音频模型:70-80分左右,目前是good enough的状态。
视频模型:目前还是比较弱的。
基于此,李沐给出了一个推论:
在长文本上的人机交互变得越发流行。

至于大模型的应用(Applicaitions),李沐认为它们本质应该是可以为用户提供无限的人力资源。

而这些应用目前在白领和蓝领职场上“上岗”或“协作”的效果如何,李沐做了个表格。
从结果上来看,只有白领、文科属性的简单工作是hold得住的。

对于应用的总结,李沐认为:
只要数据足够,万物即可被自动化。

基于李沐创业一年半的经历,他也分享了几点技术上的思考。
首先,预训练(pre-training)和后训练(post-training)是同等重要的。
其次,没有真正的垂直领域模型;再垂直的模型,它的通用能力也是差不了的。

以及,在大模型评测方面,李沐认为现在的评测太简单了,即使各种刷榜,但用起来的时候就能感受到真实效果。
因此他认为评测这件事虽然很重要,但真正做起来却很难。

除此之外,李沐还分享了几个观点:
数据定义了大模型的能力上限
自建GPU不会比租GPU便宜太多
大部分机器学习时代的经验,依旧适用于大模型时代

而除了技术之外,李沐在这次演讲中也给上交大的师生们分享了自己在职场上的心得。
谈个人“打卡式人生”
了解李沐的人或许对他的个人经历比较熟知了。
本科和研究生就读于上海交通大学,而后赴香港科技大学和CMU深造,在伯克利和斯坦福担任助理教授。
也曾任职于百度和亚马逊等科技大厂,最近的一年半则是创业BosonAI(第二次创业)。
李沐回顾自己的过往,在现场戏称为“打卡式人生”——什么样的地方都转过了一遍了。

那么李沐在经历了种种之后,是一种什么体验?
这也正是我们文章开头提到的“每天在想的基本目标”(精彩的内容必须再提一遍):
大公司:你要想如何升职加薪
博士:你要想如何毕业
创业:你要想如何“退出”(要么上市,要么卖掉)

基于这三个大方面,李沐基于自己的经验,将各自阶段的优点和缺点罗列了出来。
例如对于“打工人”这个角色,李沐的PPT刚出来,上交大的学子们便笑了出来:

读博士期间的优点和缺点是这样的:

聊到创业的优点,李沐形象地将这个过程比喻为:
可以体验当(合法)海盗的乐趣,哪儿有钱就去抢一把,没抢到就死掉了。
但李沐此次演讲的两个大part并非是割裂的,相反,是可以非常自然的做一个“有机结合”。
他认为应该从“动机”出发去解决一个问题:
有学术价值:那就去做对LLM的理解(PhD/教职)
有商业价值:那就去做LLM上的新应用(创业)
有成长价值:那就去做LMM上的产品落地(打工人)
最后,李沐老师也给了上交大学生一点Tips:

而谈到创业归来,就在前几天,李沐在知乎写的一篇文章《创业一年,人间三年》非常火爆。
不仅是李沐自述了创业一年来的进展,也在三言两语之间,展现了大佬创业的势能——
一开始没打算直接做大模型,但张一鸣建议要创业就直接大模型;买卡需要排队等不及只好给老黄写信,没想到老黄就给安排了;刚创业做游戏的“老蔡”就来交流过了——米哈游那个老蔡;在斯坦福和快手创始人宿华散步,感叹创业心得……
总之,千字短文,但细节之精彩,故事之有趣,值得多读几遍:
One More Thing
目前已经有B站网友Kimoyee将李沐老师此次的演讲视频上传,感兴趣的小伙伴们可以“深度学习”下哦~
参考链接:[1]https://www.xiaohongshu.com/explore/66c926d9000000001f01929c[2]https://www.xiaohongshu.com/explore/66c81dd5000000001f014761[3]https://www.bilibili.com/video/BV1vBWDepECq/?spm_id_from=333.337.search-card.all.click