112208/28
112208/28

在过去几年里,我们听到太多关于“如何追上英伟达”的讨论。无论是在全球的科技论坛,还是在中国的技术会议,似乎每个人都在琢磨一件事:造出一块性能强悍的GPU,击败英伟达,成为新的*。
但问题是,这真的可能吗?只靠一块GPU,就能撼动英伟达在高性能计算和人工智能领域的统治地位?
这种观点,不仅过于简单,还隐藏着巨大的盲点。
英伟达的成功,远远不止一块GPU那么简单。它背后,是一个由硬件、软件、通信和生态系统组成的“帝国”——一个全方位、无死角的技术体系。只有理解并复制这个完整的体系,才可能有机会挑战它。
而那些只盯着GPU性能的公司,注定只能停留在表面,永远无法触及到英伟达真正的护城河。
接下来,我们将深入挖掘这个“帝国”背后的秘密,看看英伟达究竟是如何构建出这个让对手望而却步的庞大体系的。
01 不仅仅是GPU,而是全方位的“帝国”架构
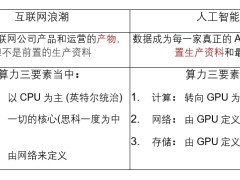
英伟达的真正力量,远不止于一块强大的GPU,而在于它打造了一个横跨硬件、软件、通信和存储的全方位“帝国”架构。这个帝国,让英伟达在高性能计算和人工智能领域,几乎无人能敌。
我们来看看英伟达的硬件家族。首先当然是Blackwell GPU,这是目前全球性能最强的并行计算引擎。然而,这只是整个硬件体系的冰山一角。
英伟达的布局中,还有Grace CPU。这是专为高性能计算和AI优化的CPU,完全适配GPU的并行计算需求。Grace与GPU的配合,使得英伟达的系统在复杂任务处理中如鱼得水。
再说BlueField DPU(数据处理单元)。它负责加速数据中心的关键任务,包括安全、存储和网络。简而言之,BlueField让英伟达的系统更智能、更安全。
还有NVlink交换机,它提供了GPU之间的超高速通信,彻底打破了传统GPU之间的瓶颈。NVlink交换机意味着什么?意味着数据在多个GPU之间流动时,几乎没有延迟,像水流一样顺畅。
这些硬件组合在一起,形成了英伟达的硬件帝国。这个帝国不仅仅是堆叠性能,它是一个经过精心设计的协同系统,让每个组件都能发挥*效能。
硬件强大不代表一切,还需要软件来调教。英伟达的CUDA平台,正是他们软件帝国的核心。它是什么?简单来说,CUDA是一套让开发者能够充分利用GPU性能的工具库和编程环境。
有了CUDA,开发者可以用最少的代码,调用最强大的并行计算资源。它不仅让英伟达的GPU如虎添翼,还构建了一个庞大的开发者社区。成千上万的软件和应用,都是基于CUDA开发的。换句话说,想用英伟达的硬件,你必须用它的“语言”。
CUDA不仅绑定了开发者,还形成了一个闭环生态。你用英伟达的GPU,就不得不依赖它的工具,而这些工具又不断强化英伟达的地位。这就是英伟达软件帝国的无形护城河。
高性能计算中,速度不仅仅是硬件计算速度,还包括数据传输的速度。这一点上,英伟达更是布局深远。
首先是NVlink,它是英伟达的秘密武器之一。NVlink提供了比传统PCIe高出数倍的带宽,保证多个GPU之间的数据交换迅速无比。对于大型AI模型训练或复杂计算任务,这种速度优势尤为关键。
还有InfiniBand,这是高性能计算中不可或缺的通信技术。英伟达通过收购Mellanox,将InfiniBand纳入麾下,进一步增强了其在数据中心级别的统治力。InfiniBand使得大规模并行计算集群中的数据传输变得更快、更稳定,极大提升了整体系统的性能。
结合以上这些,英伟达构建了一个几乎无懈可击的“帝国”架构。这个架构不仅仅在硬件上*,更在软件、通信和存储上做到了*的优化和整合。想要复制英伟达,仅仅依靠一块GPU远远不够,真正的挑战是如何打造一个类似的全方位“帝国”。
02 单靠GPU?别天真了!看懂全栈体系的真谛
GPU当然重要,但只把赌注压在GPU性能上,最终只会走进死胡同。为什么?因为高性能计算和人工智能领域,靠的从来不是单点突破,而是全栈体系的合力。
想象一下,一个超级跑车拥有最强大的引擎,却配备了劣质的轮胎和糟糕的变速箱,这辆车能跑得快吗?同理,单靠一块强大的GPU,没有一个配套的体系来支撑,依然跑不快。
我们看到,一些公司拼命追赶英伟达,在GPU性能上绞尽脑汁,却忽略了高性能计算真正的痛点——整体系统的优化和协同。这种短视的战略,看似专注,实则狭隘。
因为不论你的GPU多强,如果周边系统跟不上,你依然只能在低效的泥潭中挣扎。这就是单点突破的致命局限:你可能在一小部分性能指标上超越英伟达,但在整体表现上,还是差了十万八千里。
英伟达之所以能超越竞争对手,靠的不是一块“孤胆英雄”的GPU,而是全栈体系的全面布局。GPU只是它的核心之一,而在这核心的周围,环绕着一个精心构建的生态系统——包括CPU、DPU、通信网络、存储系统,甚至是开发工具和软件平台。
这些系统之间相互协作,形成了一个闭环。英伟达的硬件不仅性能强大,还能通过NVlink等技术无缝连接,极大地提高了数据处理的速度和效率。它的软件平台CUDA,让开发者轻松调用强大的计算资源,不需要反复“造轮子”。
这种体系化思维,才是真正的制胜法宝。英伟达不是一个硬件制造商,而是一个通过全栈技术整合,创造出*计算能力的科技帝国。
所以,想要挑战英伟达?仅仅盯着GPU,那就是天真。真正的挑战,是要拥有体系化的视野和能力,把硬件、软件、通信、存储等多个领域的技术整合成一个强大的生态系统。只有这样,才能在未来的高性能计算和人工智能战争中占据一席之地。
03 为什么连英特尔和AMD都只能望其项背?
英伟达的成功并不是一夜之间发生的。在高性能计算和人工智能的战场上,英特尔和AMD一直是强有力的竞争者,拥有雄厚的技术实力和市场经验。然而,为什么这两大巨头在面对英伟达时,似乎总是差了那么一截?
要理解这个问题,我们必须深入探讨英伟达与英特尔、AMD之间的生态系统差异。
英特尔作为全球*的半导体公司之一,拥有强大的CPU市场占有率。而AMD则以其在CPU和GPU领域的双重布局而闻名。理论上,这两家公司都有能力挑战英伟达。但事实是,他们在生态系统的构建上,始终未能达到英伟达的高度。
英特尔和AMD在技术实力上并不逊色,甚至在某些方面还有优势。但他们的短板在于缺乏英伟达那样无缝整合硬件、软件和通信网络的全栈能力。英伟达通过自己的GPU,结合Grace CPU、BlueField DPU、NVlink、InfiniBand以及CUDA生态系统,打造了一个闭环的计算帝国。
英特尔和AMD虽然各有特色,但在系统整合上,他们更多地依赖第三方的解决方案,而非自家产品的无缝协同。例如,英特尔的Xe GPU虽然技术先进,但其软件生态远不如CUDA那么成熟和广泛。AMD的Radeon GPU同样强大,但它在开发者支持和高性能计算整合上,仍然无法与英伟达的整体解决方案相提并论。
英伟达不仅提供了强大的硬件,还为开发者提供了完整的工具链和开发环境。这种软硬件结合的战略,让英伟达在竞争中占据了独特的优势。开发者不只是购买英伟达的GPU,他们也进入了英伟达的生态系统,使用CUDA编写代码,利用NVlink提升数据传输效率,甚至依赖英伟达的AI平台进行开发。这种从硬件到软件的全覆盖策略,是英伟达构建护城河的关键。
这就是为什么英特尔和AMD只能望英伟达的项背。单点的技术突破,无法替代全栈的生态体系。
04 国产GPU们要怎么打破英伟达的“帝国体系”?
在中国GPU领域,华为的昇腾是当之无愧的明星。它凭借强大的AI计算能力和自主研发的硬件,在国内市场上迅速崭露头角。看上去,昇腾似乎有希望成为中国版的“英伟达”。但事实真的如此简单吗?
昇腾的优势显而易见。它依托华为的技术实力,与自研的鲲鹏CPU、达芬奇架构AI处理器协同作战,在硬件性能上不输任何国际巨头。在国内市场,昇腾几乎成了国产高性能计算的代名词。
但问题也同样明显。首先是生态系统的局限性,与英伟达的CUDA相比,昇腾的软件生态还处于发展初期。没有一个被全球开发者广泛认可和使用的标准化工具,昇腾的影响力很难突破国内市场,更别提在国际市场上与英伟达一较高下。
其次,软硬件一体化程度不够。英伟达不仅有强大的GPU,还有无缝衔接的CPU、DPU和网络交换机,构成了一个完整的高性能计算体系。相比之下,昇腾虽然在硬件上有不俗表现,但在系统整合上,距离英伟达那种“帝国”般的全栈布局还有很长的路要走。
而且,华为在国际市场上的挑战众所周知,这也限制了昇腾在全球范围内推广其技术和生态系统的能力。没有广泛的国际开发者社区支持,昇腾很难在全球市场上取得突破。
不仅仅是昇腾,中国还有许多其他GPU厂商也在奋力追赶。例如,景嘉微在军工领域有所建树,芯动科技专注于高性能GPU,壁仞科技主攻AI推理和训练,摩尔线程则瞄准图形处理器。然而,这些厂商普遍面临同样的问题:整体系统布局不足,软件生态薄弱,市场影响力有限。各家在单点上有进展,但在全局上,难以形成对英伟达的实质性威胁。
这种分散发展的策略,就像是几条小船试图对抗一艘航空母舰。每家厂商都在自己的一亩三分地上苦苦耕耘,却缺乏彼此之间的协同和整合。结果就是,尽管各家在某些技术指标上可能超过了英伟达,但在全栈体系的竞争中,仍然无法形成合力。
最让人担忧的是,技术生态的碎片化。缺乏统一的开发平台和标准,导致国内的技术生态像是一个拼凑的拼图,开发者在使用这些国产GPU时,面临的兼容性问题和学习成本都大大增加。这不仅拖慢了技术的扩展和推广,还限制了国产GPU在国际市场上的竞争力。
05 分散的力量如何汇集,才能挑战英伟达的霸主地位?
面对英伟达的“帝国体系”,中国的GPU厂商如果继续单打独斗,简直是在自掘坟墓。想撼动这样一个巨头?醒醒吧,必须联合!
参考模式?历史早就告诉我们,分散的力量就是等着被碾压。日本汽车工业曾各自为战,被美国巨头压得喘不过气。后来呢?他们整合供应链,统一标准,迅速崛起,成为全球汽车市场的霸主。安卓阵营也是如此。当年iOS几乎垄断市场,结果谷歌带着一群厂商抱团反击,安卓最终笑到了最后。
国内GPU厂商该学会这一招了。继续各自为战,只会让英伟达继续稳坐王座。
国内联合的可行路径?华为,站出来当领头羊吧。你有技术,有市场,还有初步的生态系统。当然,只靠一个华为是不够的,而且什么市场都只给华为也不利于整个产业的发展。必须照顾到其他独立GPU厂商的利益。
这个时候,华为必须要展现出足够的心胸和格局。在业界,华为比较“独”这一点,被广为诟病。在不少领域,华为过于强势,往往阻碍了其他厂商的发展,这也不利于整个市场的健康。
在汽车领域,我们似乎看到了华为的一种开放心态。一方面,坚决不造车,不跟合作伙伴争市场;另一方面,开始从资本层面进行联合,考虑合作伙伴的利益。
在GPU领域,完全可以跟汽车领域类似,可以通过独立合资公司的方式,把昇腾和其他国产GPU厂商的力量整合起来,打造一个完整的国产计算生态系统。
在这个国产GPU厂商联合体的基础上,还需要一个统一的开发平台和生态。看看英伟达的CUDA,已经绑死了全球的开发者。我们也得搞一个。统一的平台,统一的标准,才能吸引开发者,才能形成合力。否则,各干各的,注定被分而治之。
政府也不能袖手旁观。政策引导、资金支持、标准制定,都得跟上。只靠市场自发合作?别天真了,政府不出手,这场仗没法打。
看看历史上的成功案例。PC时代的“Wintel联盟”——微软和英特尔联手,硬生生地把PC市场变成了他们的天下。现在,中国GPU厂商也必须走这条路。联合起来,形成软硬件结合的合力,才能在全球市场上挑战英伟达。
继续单打独斗,只会让市场更加分裂,最后谁也赢不了。现在是关键时刻,选择联合,才能生存。选择分散,只会被淘汰。
中国GPU产业,必须抓住这次机会。联合起来,才能在全球市场上真正站稳脚跟。否则,一切努力都将白费。
06 大模型,给了我们一次“平等”竞争的机会
英伟达的先发优势已经稳固如铁。后进者想要撼动它,几乎是不可能的任务。然而,中国市场或许在未来五年内,有机会构建出一个“小英伟达”。听起来像天方夜谭,但其实有理有据。
美国对中国的技术限制,尤其是在高端GPU领域的限制,反而给我们带来了一个“政策墙”。这道墙不是障碍,而是屏障,为国产GPU的成长预留了一定的市场空间。在这片空间里,我们有机会培养出自己的技术力量,不至于被英伟达压得透不过气。
然而,比政策保护更为关键的,是大模型对整个产业的重构。英伟达在AI领域深耕多年,但在大模型这一全新的战场上,它其实并没有那么强大的先发优势。大模型本身就是一个新生事物,所有人都在同一起跑线上,包括英伟达。
这就意味着,只要我们聚焦大模型,集中力量,特别是在GPU算力方面下大力气投资,完全有可能实现“弯道超车”。
华为的鸿蒙系统就是一个很好的例子。鸿蒙的成功,不仅得益于政策保护,更重要的是,它赶上了操作系统从手机向物联网的技术变革期。正是这一变革期,给了鸿蒙突围的机会。
现在,GPU领域也正处于类似的变革期。大模型的崛起正在重构整个产业格局,这是中国企业必须抓住的历史性机遇。而且,这一次,不能只有华为在战斗,其他GPU厂商也必须联合起来,形成合力,共同推进国产GPU的发展。
未来五年内,能不能在中国市场上崛起一个“小英伟达”,关键在于我们能否抓住这次大模型带来的变革机遇。机会摆在眼前,成败在此一举。