88805/15
88805/15

“如果发布的是GPT-5,那OpenAI依然遥遥*。如果是AI Search或者是语音助手,那就说明OpenAI没落了。”
一位AI大模型从业者告诉虎嗅,业内对OpenAI的期待太高,除非是GPT-5这样的颠覆式创新,否则很难满足观众的“胃口”。
虽然Sam Altman在OpenAI线上直播前,已经预告不会发布GPT-5(或GPT-4.5),但外界对OpenAI的期待早已是九牛拉不转了。
北京时间5月14日凌晨,OpenAI公布了最新的GPT-4o,o代表Omnimodel(全能模型)。20多分钟的演示直播,展示了远超当前所有语音助手的AI交互体验,与外媒此前透露的消息基本重合。
虽然GPT-4o的演示效果仍可称得上“炸裂”,但业内人士普遍认为很难配得上Altman预告中的“魔法”二字。很多人认为,这些功能性的产品,都是“偏离OpenAI使命”的。
OpenAI的PR团队似乎也预料到了这种舆论走向。发布会现场以及会后Altman发布的博客中对此解释道:
“我们使命的一个关键部分是将非常强大的人工智能工具免费(或以优惠的价格)提供给人们。我非常自豪我们在ChatGPT中免费提供了世界上*的模型,没有广告或类似的东西。
当我们创办OpenAI时,我们最初的想法是我们要创造人工智能并利用它为世界创造各种利益。相反,现在看起来我们将创造人工智能,然后其他人将使用它来创造各种令人惊奇的事物,让我们所有人都受益。”
遥遥*的GPT-4o
“如果我们必须等待5秒钟才能得到‘每个’回复,用户体验就会一落千丈。即使合成音频本身听起来很真实,它也会破坏沉浸感,让人感觉毫无生气。”
在OpenAI发布会前夕,英伟达Embodied AI负责人Jim Fan在X上预测了OpenAI会发布的语音助手,并提出:
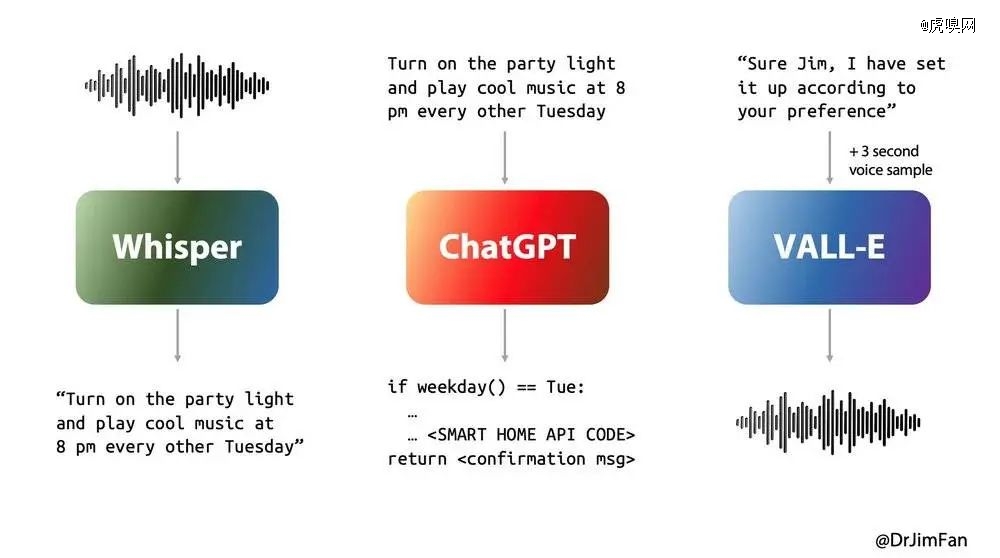
几乎所有的语音AI都会经历三个阶段:
1.语音识别或“ASR”:音频->文本1,例如Whisper;
2.计划下一步要说什么的LLM:text1 -> text2;
3.语音合成或“TTS”:text2 ->音频,例如ElevenLabs或VALL-E。
经历3个阶段会导致巨大的延迟。
GPT-4o在响应速度方面,几乎解决了延迟问题。GPT-4o的响应音频输入的最短时长为232毫秒,平均响应时长320毫秒,几乎与人类相似。没有使用GPT-4o的ChatGPT语音对话功能平均延迟为2.8秒(GPT-3.5)和5.4秒(GPT-4)。
GPT-4o不仅通过缩短延迟极大地提升了体验,还在GPT-4的基础上做了很多升级包括:
*的多模态交互能力,包括语音、视频,以及屏幕共享。
可以实时识别和理解人类的表情,文字,以及数学公式。
交互语音感情丰富,可以变换语音语调、风格,还可以模仿,甚至“即兴”唱歌。
超低延时,且可以在对话中实时打断AI,增加信息或开启新话题。
所有ChatGPT用户均可免费使用(有使用上限)。
速度是GPT-4 Turbo的2倍,API成本低50%,速率限制高5倍。
“没落”的OpenAI
“这些局限性的突破都是创新。”
有业内专家认为,GPT-4o的多模态能力只是“看起来”很好,实际上OpenAI并未展示对于视觉多模态来说真正算是“突破”的功能。
这里我们按大模型行业的习惯,对比一下隔壁厂Anthropic的Claude 3。
Claude 3的技术文档中提到,“虽然Claude的图像理解能力是尖端的,但需要注意一些局限性”。
其中包括:
人物识别:Claude不能用于在图像中识别(即姓名)人物,并将拒绝这样做。
准确性:Claude在解释200像素以下的低质量、旋转或非常小的图像时,可能会产生幻觉或犯错误。
空间推理:克劳德的空间推理能力有限。它可能很难完成需要精确定位或布局的任务,例如读取模拟钟面或描述棋子的确切位置。
计数:Claude可以给出图像中物体的近似计数,但可能并不总是精确准确的,特别是对于大量小物体。
AI生成的图像:Claude不知道图像是否是人工智能生成的,如果被问到,可能不正确。不要依赖它来检测假图像或合成图像。
不适当的内容:Claude不会处理违反我们可接受使用政策的不适当或露骨的图像。
医疗保健应用:虽然Claude可以分析一般医学图像,但它不是为解释CT或MRI等复杂诊断扫描而设计的。Claude的输出不应被视为专业医疗建议或诊断的替代品。
在GPT-4o网站发布的案例中,有一些与“空间推理”有相关的能力,但仍难算得上突破。
此外,从发布会现场演示中GPT-4o输出的内容很容易看出,其模型能力与GPT-4相差并不大。
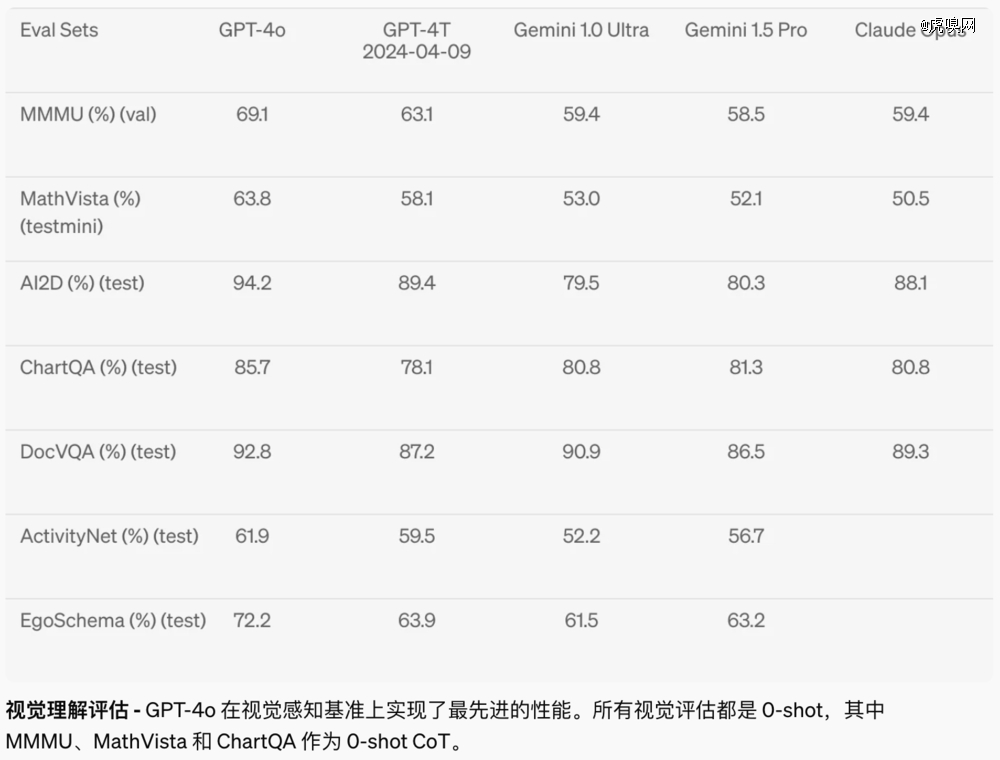 GPT-4o跑分
GPT-4o跑分
虽然模型可以在对话中增加语气,甚至即兴演唱,但对话内容还是与GPT-4一样缺乏细节和创造力。
此外,发布会后OpenAI官网还发布了GPT-4o的一系列应用案例探索。包括:照片转漫画风格;会议记录;图片合成;基于图片的3D内容生成;手写体、草稿生成;风格化的海报,以及连环画生成;艺术字体生成等。
而这些能力中,照片转漫画风格、会议记录等,也都是一些看起来很普通的文生图或者是AI大模型功能。
能挑战现有的商业模式吗?
“我注册5个免费的ChatGPT账号,是不是就不需要每月花20美元订阅ChatGPT Plus呢?”
OpenAI公布的GPT-4o使用政策是ChatGPT Plus用户比限制普通用户的流量限制高5倍。
GPT-4o对所有人免费,首先挑战的似乎是OpenAI自己的商业模型。
第三方市场分析平台Sensor Tower公布的数据显示,过去一个月中,ChatGPT在全球App Store中的下载量为700万,订阅收入1200万美元;全球Google Play市场的下载量为9000万,订阅收入300万美元。
目前,ChatGPT Plus在两个应用商店的订阅价格均为19.99美元。由订阅数据推断,ChatGPT Plus过去一个月中,通过应用商店付费的订阅用户数为75万。虽然ChatGPT Plus还有大量的直接付费用户,但从手机端的收入来看,每年进项才不到2亿美元,再翻几倍也很难撑起OpenAI近千亿的估值。
由此来看,OpenAI在个人用户充值方面,其实并不需要考虑太多。
更何况GPT-4o主打体验好,如果你跟AI聊着聊着就断了,还要换账号重新聊,那你会不会愤然充值呢?
“最初的ChatGPT暗示了语言界面的可能性;这个新事物给人的感觉有本质上的不同。它快速、智能、有趣、自然且有帮助。”
Sam Altman的最新博客中提到了“语言界面的可能性”,这也正是GPT-4o接下来可能要做的:挑战所有GUI(图形交互界面),以及想要在LUI(语音交互界面)上发力的人。
结合近期外媒透出的OpenAI与苹果合作的消息,可以猜测GPT-4o可能很快就要对所有AI PC、AI手机的厂商“抛橄榄枝”或是“掀桌子”。
不管是哪种语音助手或是AI大模型,对于AIPC、AI手机来说核心价值都是优化体验,而GPT-4o一下把体验优化到了*。
GPT-4o很可能会卷到所有已知的App,甚至是SaaS行业。过去一年多时间里,市场上所有已经开发和正在开发的AI Agent都会面临威胁。
某位资源聚合类app产品经理曾对虎嗅表示,“我的操作流程就是产品的核心,如果操作流程被你ChatGPT优化了,那相当于我的App没价值了。”
试想,如果订外卖的App,UI变成了一句话“给我订餐”,那打开美团还是打开饿了么,对于用户来说就一样了。
厂商的下一步只能是压缩供应链、生态的利润空间,甚至是恶性价格战。
从目前的形式来看,其他厂商要在模型能力上打败OpenAI恐怕还需要一段时间。
产品要对标OpenAI,可能只有通过做更“便宜”的模型了。
对于国内产业的影响
“最近忙死了,没顾上关注他们。”
一位工业AI大模型创始人告诉虎嗅,近期一直在忙着沟通战略合作、产品发布、客户交流资本交流,完全没有时间关注OpenAI这种发布。
OpenAI发布前,虎嗅也询问了多位来自各行各业的国内AI从业者,他们对OpenAI最新发布的预测与看法都很一致:非常期待,但与我无关。
一位从业者表示,从国内目前的进度来看,要在短期内追上OpenAI不太现实。所以关心OpenAI发布了什么,最多也就是看看最新的技术方向。
目前国内公司在AI大模型研发方面,普遍比较关注工程化和垂直模型,这些比较务实、容易变现的方向。
在工程方面,近期蹿红的Deepseek就正在国内大模型行业中掀起Token的价格战。在垂直模型方面,多位业内人士告诉虎嗅,短期内小模型和垂直模型的研发,基本都不会受到OpenAI的裹挟。
“有时候OpenAI的技术方向也不是很值得借鉴。”一位模型专家对虎嗅表示,Sora就是个很好的例子,2024年2月OpenAI发布了视频模型Sora,实现了60秒的视频稳定输出。虽然看起来效果很好,但后续的实践几乎没有,落地速度也非常慢。
在Sora之前,国内很多在文生视频领域发力的公司和机构已经实现了15秒稳定视频生成,而Sora出来以后,一些公司的研发、融资、产品节奏都被打乱了,甚至使整个文生视频行业的发展演变成了一场“技术的大跃进”。
所幸,这次GPT-4o与Sora大有不同。OpenAI CTO Muri Murati表示,在接下来的几周内,我们将继续我们的迭代部署,为您提供所有功能。
发布会结束不久,GPT-4o就已经可以上线试用了。