253805/10
253805/10

今年2月发布的Sora,先是引得业界“哇声一片”,马斯克直接表态「人类愿赌服输」;周鸿祎说借助Sora人类实现AGI将缩减至一两年。
大佬的彩虹屁不是白吹的。利用Diffusion+Transformer架构,Sora借助图像处理、空间关系、物理规律、因果逻辑等规律与知识,在十几秒、几十秒的视频中完成对现实世界的解构与再造。
但没过多久人们就发现,再多的“哇声一片”也改变不了Sora算法闭源的事实,意味着它无法复现。留给外界的是一道单选题:要么加入,要么自研。
1
变局
在Sora发布后两个月,大洋彼岸突然有一家初创公司,与清华大学联手,推出了一款号称“继Sora后*完成突破的视频大模型”——Vidu。
这是中国*长时长、高一致性、高动态性的视频大模型。在官方介绍中,Vidu采用原创U-ViT架构,结合Difusion与Transformer技术,能够一键生成长达16秒、1080P分辨率的高清视频。
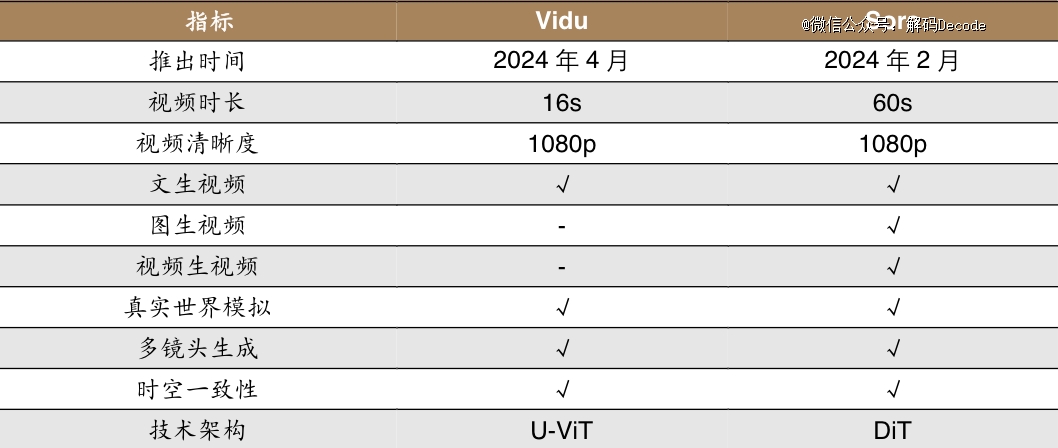
在对标Sora的性能指标里,Vidu也只有在时长和图/视频生视频上不敌。按照业内的评价,Vidu性能直接对标国际*水平,并在加速迭代提升中。
从Vidu放出的官方视频来看,它几乎展示了视频大模型需具备的所有核心能力:多镜头生成、模拟真实世界、保持时空一致性、丰富的想象力,以及让老外难以搞懂的中国元素。
作为“镜头语言”,多镜头生成是视频大模型的一堂必修课。现有的AI生成视频,大多都只包含了轻微幅度的推、拉、移等简单镜头,镜头语言单调而且也没什么叙事感,这是硬伤。
究其原因,是因为现有视频内容沿用的技术路径大多通过图片的插帧和拼接而成,无法完成长时序的连贯预测。
Vidu似乎没有上述问题,不仅能够围绕统一主体在一段画面里实现远、中、近景、特写等多样化镜头切换,还能直接生成转场、追焦、长镜头等效果,包括能够生成影视级的镜头画面。
AI视频生成的另一个难题是,较难突破画面时空一致性与场景。什么是画面时空一致性,翻译过来就是在没有任何转场的情况下不能突变。一个典型的例子就是某些大模型的视频中,一只猫走着走着就变成了6只脚。
Vidu在一定程度上也克服了这个问题,起码从它生成的一段“带珍珠耳环的猫”的视频中可以看到,随着镜头的移动,作为画面主体的猫在3D空间下能够一直保持服饰、表情、模态的一致,视频整体看上去非常的连贯、统一和流畅。
模拟真实物理世界运动同样是视频大模型的核心,Vidu在对外放出的展示视频中,有一段明显是瞄着Sora打:模拟“一辆老式SUV行驶在山坡上”,Vidu的表现堪称*,灰尘、光影、背景等细节与真实世界中人类的感知几乎无差。
在对不存在的超现实主义画面解构上,Vidu也能做到“合理的奇幻”。例如,“帆船”、“海浪”能够合理地出现在画室里,而且海浪与帆船的整体交互背景非常恰当自然。
当然,作为本土团队开发的视频大模型,Vidu对中国元素的理解远超那些舶来品,比如熊猫、龙、宫殿场景等。
德邦证券在一份研报中给予了Vidu高度评价:
虽然在视频时长、视频效果、支持模态多样性等方面相比Sora仍有提升空间,但是在以镜头语言为代表的动态性,以及对物理世界规律的理解与模拟能力等方面已做到了Sora相近水平。
最后还不忘给Vidu贴上一个鲶鱼标签,意思是它或将激励国产多模态大模型突破创新。那么问题来了,凭什么是Vidu?
2
U-ViT架构
Vidu背后的生数科技,并不是一家名不见经初创企业。
OpenAI曾披露过一份技术报告,显示Sora的核心技术架构源自一篇名为《Scalable Diffusion Models with Transformers》的论文,论文提出了一个将 Diffusion(扩散模型)和 Transformer融合的架构——DiT,也就是后面被Sora采用的那个。
而在DiT提出前两个月,清华团队就提出了用Transformer替代基于CNN的U-Net的网络架构U-ViT,也就是Vidu采用的那个。甚至,据极客公园报道,因为U-ViT更早发布,计算机视觉顶会CVPR 2023收录了清华大学的U-ViT论文,却以「缺乏创新」为由拒稿了Sora底层使用的DiT论文。
生数科技的核心团队就源于清华大学该论文团队,CTO鲍凡正是该篇论文的一作。严格意义说,Vidu并不是“国产Sora”,而是一棵树上的两朵花。
之所Vidu能在两个月内快速突破16s流畅视频生成,核心就在于团队对U-ViT架构的深入理解以及长期积累的工程与数据经验。而且据透露,3月份内部就实现了8秒的视频生成,紧接着4月份就突破了16s生成。
简单来说,在架构上U-ViT也是Diffusion和Transformer融合的架构,路径以及部分结论都是相似的
U-ViT与DiT二者均提出了将Transformer与扩散模型融合的思路,即以Transformer的网络架构替代基于CNN的U-Net架构,并且具体的实验路径也是一致的。比如,二者采用了相同的patch embedding、patch size;二者得出了同样的结论:patch size为2*2是最理想的。
不同于采用插帧等处理长视频的方法,U-ViT架构在感官上注重“一镜到底”,视频质量更为连贯与自然。从底层来看,这是一种“一步到位”的实现方法,基于单一模型完全端到端生成,不涉及中间的插帧和其他多步骤的处理,文本到视频的转换是直接且连续的。
有了理论支撑,就要考研团队的工程化能力了。所谓工程化,抽象点说就是增强产品的架构设计,提升产品模块的复用性和扩展性。
2023年3月,基于U-ViT架构,生数科技团队开源了全球*基于U-ViT融合架构的多模态扩散模型UniDiffuser,率先完成了U-ViT架构的大规模可扩展性验证,比同样DiT架构的Stable Diffusion 3*了一年。
UniDiffuser是在大规模图文数据集LAION-5B上训练出的近10亿参数量模型,支持图文模态间的任意生成和转换,具有较强的扩展性。简单来讲,除了单向的文生图,还能实现图生文、图文联合生成、无条件图文生成、图文改写等多种功能。
视频本质是图片的集合,实现图像在时间维度的扩增,这使得图文任务取得的成果往往可以在视频领域复用。
例如,Sora采用了DALL・E 3的重标注技术,通过为视觉训练数据生成详细的描述,使模型能够更加准确地遵循用户的文本指令生成视频。Vidu同样复用了生数科技在图文领域的众多经验,靠的就是扎实的工程化能力。
根据甲子光年,生数科技团队通过视频数据压缩技术降低输入数据的序列维度,同时采用自研的分布式训练框架,在保证计算精度的同时,通信效率提升1倍,显存开销降低80%,训练速度累计提升40倍。
目前,Vidu仍在加速迭代,未来将从图任务的统一到融合视频能力持续升级,灵活的模型架构也将能够兼容更广泛的多模态能力。
3
加速向应用端延伸
以Open AI与Google为代表的科技巨头,正在海外掀起一场多模态“军备竞赛”,而*的目标之一正是视频领域的加速迭代。
先是OpenAI CEO年初密集“剧透”GPT-5,相比GPT-4实现全面升级,其中将支持文本、图像、代码和视频功能,或将实现真正的多模态。紧接着就是2月发布的Sora,能够根据文本指令或静态图像生成1分钟的视频。
Google也不遑多让,推出的原生多模态大模型Gemini可泛化并无缝地理解、操作和组合不同类别的信息。而2月推出的Gemini 1.5 Pro,则使用MoE架构首破100万极限上下文纪录,可单次处理包括1小时的视频、11小时的音频、超过3万行代码或超过70万个单词的代码库。
国内也不甘人后,除生数科技发布Vidu外,潞晨科技对其开源文生视频模型Open-Sora 进行了大更新,现在可生成16秒,分辨率720P的视频。同时具备可以处理任何宽高比的文本到图像、文本到视频、图像到视频、视频到视频和无限长视频的多模态功能,性能加速向Sora靠齐。
而国内外疯狂押注的底层逻辑是,多模态提升了大模型的泛化能力,在多元信息环境下实现了“多专多能”。多模态尤其是视频大模型的成熟成为奠定AIGC应用普及的基础,在垂直领域具有广阔的应用场景和市场价值。
比如上个月Adobe就宣布,将Sora、Pika、Runway等集成在视频剪辑软件Premiere Pro中。在发布短片中,Premiere Pro展现出了在视频中添加物体、消除物体以及生成视频片段等能力。
通过AI驱动的音频功能已普遍可用,可使音频的编辑更快、更轻松、更直观。而AI驱动的视频功能,将是多模态大模型在AIGC应用融合中的重要尝试,更深层的意义是,它或将催生未来更多现象级应用的开发。