75604/25
75604/25

上周,meta发布了其最新开源模型Llama3,提供8B和70B的预训练和指令微调版本,号称是最强大的开源大语言模型。据了解,基于最新的 Llama 3 模型,meta 的AI 助手现在已经覆盖 Instagram、WhatsApp、Facebook等全系应用。而近日,meta趁热打铁,又宣布向第三方制造商开放自家的meta HorizonOS,允许其他公司基于其生态系统设计更多头戴显示器。联想、微软和华硕都是meta的首批合作伙伴。
看来,这是将开源进行到底,从大模型开源,到头显设备操作系统的开放。这也类似谷歌对安卓系统的开放模式。
不过,安卓系统整体并非一个完全开源的软件,比如Gmail、谷歌地图、Google Play、Chrome等一系列谷歌自家应用就是闭源的。毕竟,由于GPL v2许可证的关系,谷歌无法将安卓作为一个软件整体进行授权收费。谷歌其实只是理论上开放安卓,然后通过其他方式赚钱。
但大模型的开源,未来的盈利路线其实是很明确的——首先吸引更多的开发者参与到开源模型的改进和优化中来,而这些优化建议同样可以在闭源大模型中复用,大模型生态建设建设好之后,meta就可以靠提供相关的技术支持、API授权等收费。
更多企业同样看准了开源的好处,4月23日晚,微软在官网开源了小参数的大语言模型——Phi-3-mini。据了解,Phi-3-mini参数只有38亿,训练数据却高达3.3T tokens,比很多数百亿参数的模型训练数据都要多,这也是其性能*的主要原因之一。微软表示,在未来几周内还会发布70亿参数的Phi-3-small和140亿参数的Phi-3-medium两款小模型。其中,Phi-3-medium的性能可媲美Mixtral 8x7B 和GPT-3.5,资源消耗却更少。
闭源阵营对手强大,开源阵营同样正不断有强手涌入。
那么,以OpenAI为代表的闭源阵营和Llama为代表的开源阵营,到底谁会成为以后的主导?
1、开源Llama 3实力如何
对于用户来说,不管闭源开源,“抓到耗子才是好源”。
从训练的角度,Llama3对中文并不友好。在15T Tokens的训练数据,仅有5%是为非英文数据,涵盖30多种语言,其中中文就更少了。据Hugging Face第三方大模型跑分测评数据,Llama3 70B性能已经超过部分早期版本GPT4。
据国内CLUE中文语言理解测评基准最新测评,Llama3-70B在代码能力上略低于GPT-4;在中文数学能力上基础难度(1-3步推理)与GPT4-Turbo、Claude3—Opus相差不多,在4-5步数学推理任务上还有一定优化空间。测评说得比较客气,其实就是说,英文上表现不错,中文上差距还比较明显。
而meta首席人工智能科学家杨立昆则在推特上分享,Llama-3在Arena排行榜中已经位居第五。
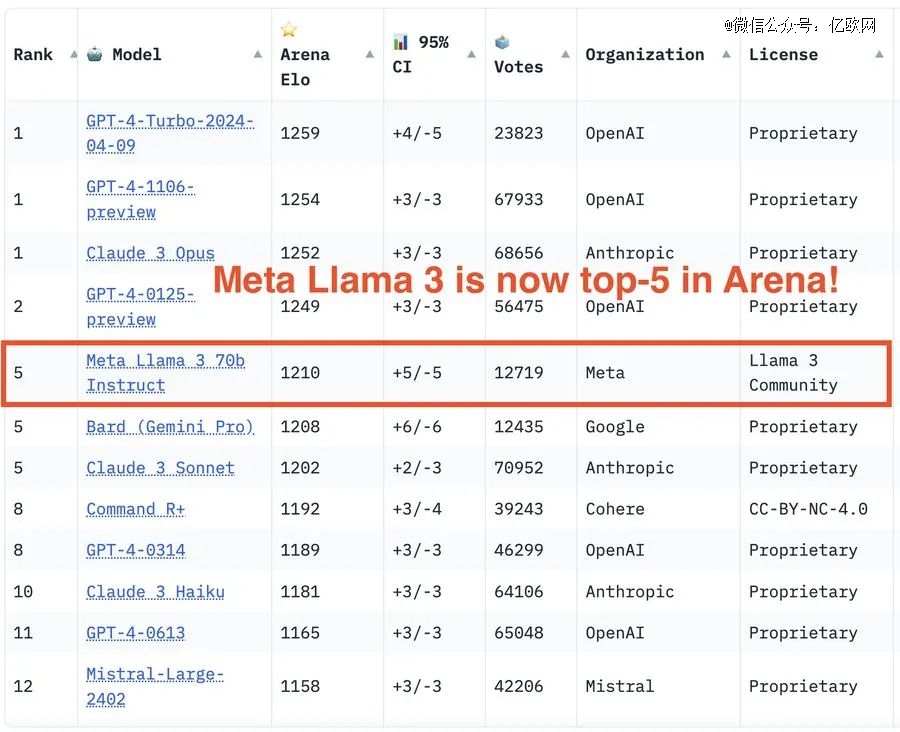
英伟达高级科学家Jim Fan也表示,“Llama3-400B+ 将标志着社区获得 GPT-4 级模型的开放权重访问权的分水岭时刻。它将改变许多研究工作和草根初创公司的计算方式。我在 Claude 3 Opus、GPT-4-2024-04-09 和 Gemini 上拉了数据,Llama-3-400B仍在训练中,希望在接下来的几个月里会变得更好。有如此多的研究潜力可以通过如此强大的能力释放,期待整个生态系统的建设者能量激增!”
不管是同行抬轿子,还是自己王婆卖瓜,至少看起来,Llama3实力非凡。而大模型性能只要能超过早期GPT4水平,就意味着已经具备较强智能,可以作为生产力工具,去替代人类完成各类业务流的碎片、繁杂工作。
GroqCloud还提供云支持,可以让用户在没有本地强大GPU的情况下使用Llama-3的8B和70B两个版本大模型。基于LLama3的中文微调,国内也已经有不少开发人员正在测试中,比如用Ollama来本地部署LLama3进行训练。
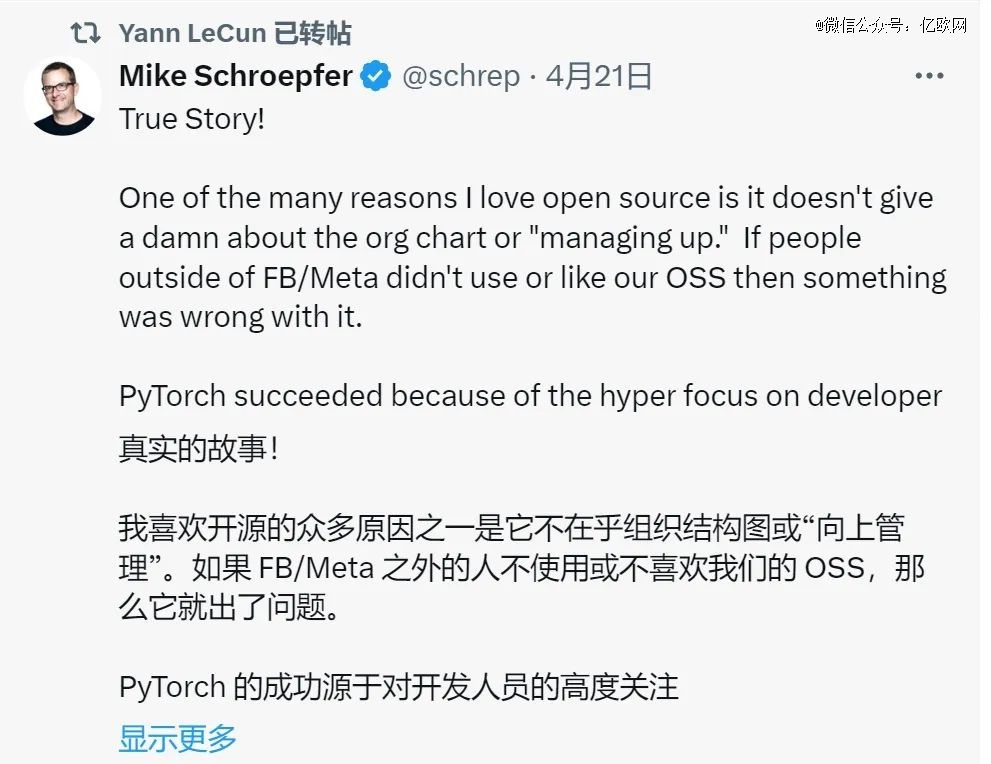
8B 和 70B 两个型号的模型,仅仅标志着 Llama 3 系列的开端,meta AI首席科学家杨立昆在其社交媒体透露,在接下来的几个月,还会有更多版本陆续发布。杨立昆还转帖分享了关于meta支持开源的真实故事。
不过,百度CEO李彦宏近日在Create2024百度AI开发者大会上表示,大模型开源意义不大,闭源模型性能会不断提升。“有了文心大模型4.0,我们可以根据需要兼顾效果、响应速度、推理成本等各种考虑,裁剪出适合各种场景的更小尺寸模型,且支持精调和post pretrain。通过降维裁剪出的模型,比直接拿开源调出来的模型,同等尺寸下效果更好,同等效果下成本明显更低。”
李彦宏认为闭源才拥有真正的商业模式,能够赚到钱,能聚集人才和算力。“闭源在成本上反而是有优势的,只要是同等能力,闭源模型的推理成本一定是更低的,响应速度一定是更快的。”同时,开源大模型的模式与传统的开源软件不同,并不是众人拾柴火焰高。因此,“未来开源模型会越来越落后”,其实在大模型场景下,开源是最贵的。
而前 DeepMind 和 meta 员工创立的初创公司 Mistral AI 尽管也是开源的大力支持者。但该团队也计划在2024年筹集更多资金,以打造除开源产品之外的消费产品。毕竟,光开源不挣钱是无法长久的,特别是对创业团队。
但周鸿祎、王小川等业内大咖对于开源大模型落后论并不认同,先后在不同场次对此提出质疑。据报道,王小川在微信群讨论中表示,“关于开闭源之争,核心是要看谁在开源?双轮驱动,是一线创业AGI公司的*解。”
第二十七届哈佛中国论坛上,周鸿祎就表示,他一直相信开源的力量,“一句话,今天没有开源就没有Linux,没有Linux就没有互联网,就连说这话的公司自己都借助了开源的力量才成长到今天。”
大佬们议论纷纷,其实谁都没有给出明确的答案。
2、开源与闭源,非得做选择题吗
李彦宏说得也没错,Llama系列并不是一个真正由大家一起来协同开发的产品。
据了解,大模型开源的方式主要有两种模式, Restrict License(限制许可)与 Apache。Llama的开源属于前者,在开放源代码的同时,对使用、修改和分发该模型的行为施加一定的限制。这与完全开放的开源许可证(如MIT、Apache 2.0等)不同,后者通常允许用户在几乎不设限的情况下使用和修改软件,Mistral、谷歌的开源模型Gemma都采取了这种方式。但哪怕后者,对于训练的数据和训练过程同样并不开源。
如果开源大模型最终的商业化还是要闭源,那就得看看闭源大模型们在做什么。
就拿最近大火的闭源大模型月之暗面为例吧。据界面新闻记者从多个渠道获悉,上一轮融资完成后,月之暗面(Moonshot AI)创始人杨植麟通过售出个人持股已套现数千万美金。由于杨植麟持股比例高达78.968%,出售部分股权似乎无可厚非?但也有投资人表示,“公司成立*年就套现这么多,这种情况并不多见。”
不过,月之暗面已经回应媒体:上述消息不实,月之暗面此前已公布员工激励计划。
套现谣传暂不讨论。但月之暗面的长文本能力,也面临被追赶的问题,毕竟长文本优势难以长期独占。不过,这是月之暗面作为初创公司要面临的问题,并不是闭源大模型行业的问题。
无论开源还是闭源,国内大模型玩家,往往呈现业界每出现一次突破性的进展,其他玩家就会快速跟进的窘境——这就意味着,创新容易被模仿,最后拼的只能是血槽厚不厚。对于B端客户而言,如果对接小厂出现不确定性,转向服务更为成熟的大厂就顺理成章。当然,月之暗面至少不打算做B端,想必也是知道B端客户的多变。
反倒是C端客户,不在乎用的大模型是不是巨头做出来的,只要好用、有一些功能切中自己需求就行。
杨植麟一直是闭源大模型的拥趸。他曾在腾讯新闻、36氪的专访中表示,开源落后于闭源是个事实。因为现在开源本身还是中心化的,开源的贡献可能很多都没有经过算力验证。闭源会有人才聚集和资本聚集,最后一定是闭源更好;反而是落后者才会开源,“搅局嘛,反正不开源也没价值”。
他认为,开源和闭源在整个生态里面会扮演不同的角色,开源很大的作用是在To B端的获客,如果想做头部的Super App,大家肯定都是用闭源模型去做的,在开源模型上做C端应用很难做出差异化。
不过,不同于月之暗面、百度押注闭源,更多大模型企业选择开源和闭源并行,例如Google、阿里巴巴、昆仑万维、零一万物、百川智能等。比如百川智能开源Baichuan2-7B、Baichuan2-13B、Baichuan2-13B-Chat 与其4bit 量化版本;但还有一些说明却没有“用大字”标注清楚——那就是这些开源的模型不算大,而且与百川智能的闭源模型相比性能差别较大。
开源大模型们似乎都财大气粗,不计较营收。至少生态上,基于开源模型也带来更多百花齐放的产品,比如Llama中文社区最近完成了对Llama3两个模型的中文能力优化,并推出了中文微调版供用户试用;还有更多基于Llama3的轻创业项目在启动。因为,大家节省了大量训练的成本,只需要投入少量的微调成本即可快速上线一个垂直领域AI应用。
而闭源大模型们则都为了拿到大模型落地订单、争夺客户而卷生卷死。
从性价比角度,目前在开源模型上进行相应的训练和微调比GPT3.5还是具备一定的价格优势。据了解,Llama2-70b的微调价格是4美元/100万token,而GPT3.5则要8美元/100万token。但价格是会变化的,未来闭源模型一样可以提供足够高的性价比。
那么,大模型领域的创业者们如何找到PMF(Product Market Fit)?
其实,开源和闭源都不是重点。创业者没必要二选一,完全可以全都要,从而找到最适合自己的底层模型并训练出有商业化潜力的垂直模型。甚至国内的一些闭源大模型,也是基于开源Llama的套壳,再叠加专业垂直领域数据集的训练,从而应用于细分领域。
乔布斯曾说:“我愿意把我所有的科技去换取和苏格拉底相处的一个下午。”
但对于坚持闭源或者开源大模型的大佬来说,自己立场对面的那些“讨厌嘴脸”们,应该是不值得自己用所有科技换取一个下午的。