109204/25
109204/25

苹果公司突然公布了一则大新闻。
北京时间4月25日凌晨,苹果在 Hugging Face 平台上发布一个“具有开源训练和推理框架的高效语言模型”,名为 OpenELM。
据了解,OpenELM有四种尺寸:2.7亿、4.5亿、11亿和30亿个参数版本,定位于超小规模模型,而微软Phi-3模型为38亿。这种小模型运行成本更低,可在手机和笔记本电脑等设备上运行。
同时,在WWDC24开发者大会之前,苹果彻底开源了OpenELM模型权重和推理代码,数据集和训练日志等。而且,苹果还开源了神经网络库CoreNet。

早在今年2月,苹果公司CEO蒂姆·库克(TimCook)就表示,苹果生成式 AI 功能将于“今年晚些时候”推出,有消息称即将在6月发布iOS 18可能是苹果iOS史上“*”的更新,而9月也将推出*AI iPhone设备。
如今,苹果似乎在新一轮AI浪潮快到尾声的时刻追赶上了行业脚步。
1、预训练tokens数量减一半,11亿参数苹果模型效果却比竞品更精准
随着ChatGPT风靡全球,近几个月来,三星、谷歌、小米等手机厂商全面推进大语言模型在手机、平板等端侧上的使用,包括照片处理、文字处理增强等,并形成一大卖点。而苹果很少透露并极少有类似的自带功能,主要是用第三方工具做到类似效果。
今年2月财报会议上,库克首次公布生成式 AI 计划,并将在今年晚些时候将 AI 技术集成到其软件平台(iOS、iPadOS 和 macOS)中。
库克表示,“我只想说,我认为苹果在生成式 AI 和 AI 方面存在着巨大的机会,无需透露更多细节,也无需超出自己的预期。展望未来,我们将继续投资于这些和其他将塑造未来的技术。其中包括 AI,我们继续在 AI 领域花费大量时间和精力,我们很高兴能在今年晚些时候分享我们在该领域正在进行的工作的细节。我们对此非常兴奋。”
实际上,自年初至今,苹果在生成式 AI 领域动作不断。今年3月,苹果技术团队发表论文《MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training》,首次披露苹果大模型MM1,涵盖300亿参数、支持多模态、支持MoE架构,超半数作者属于华人。
如今,针对手机、平板等端侧领域,苹果真正的开源模型终于来了。
据论文显示,苹果开源了大语言模型OpenELM,有指令微调和预训练两种模型版本,共有2.7亿、4.5亿、11亿和30亿4种参数,提供生成文本、代码、翻译、总结摘要等功能。
虽然最小的参数只有2.7亿,但苹果使用了包括RefinedWeb、去重的PILE、RedPajama的子集和Dolma v1.6的子集在内的公共数据集,一共约1.8万亿tokens数据进行了预训练,这也是其能以小参数表现出*性能的主要原因之一。
例如,11亿参数的OpenELM,比12亿参数的OLMo模型的准确率高出2.36%,而使用的预训练数据却只有OLMo的一半。
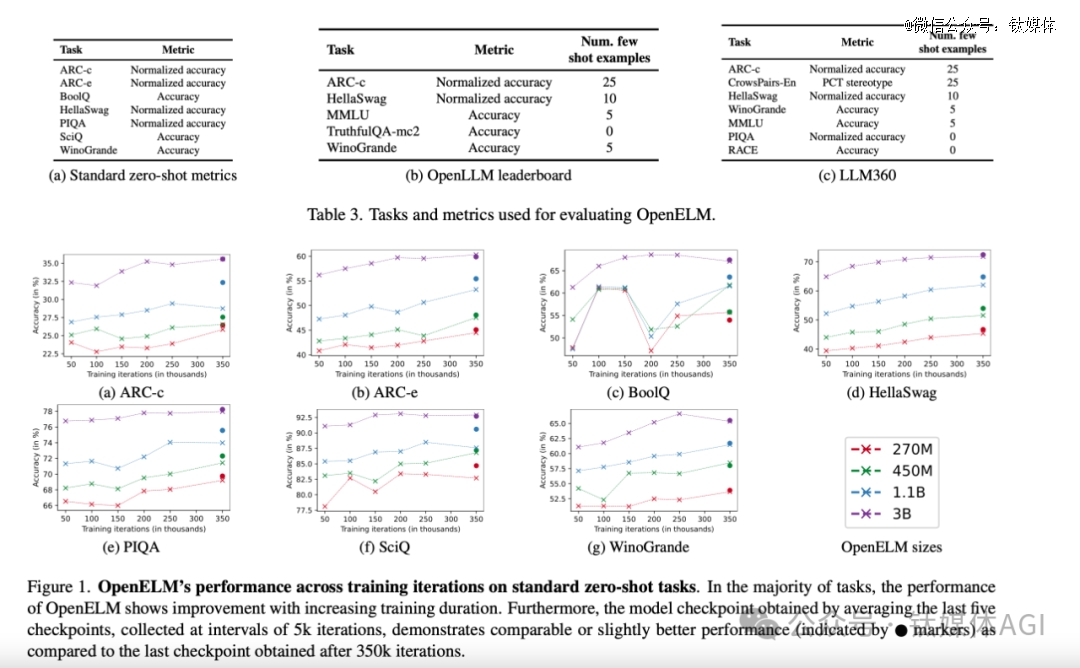
在训练流程中,苹果采用了CoreNet作为训练框架,并使用了Adam优化算法进行了35万次迭代训练。而苹果的MobileOne、CVNets、MobileViT、FastVit等知名研究都是基于CoreNet完成的。
苹果在论文中还表示,与以往只提供模型权重和推理代码并在私有数据集上进行预训练的做法不同,苹果发布的版本包含了在公开数据集上训练和评估语言模型的完整框架,包括训练日志、多个检查点和预训练配置。同时,苹果还发布将模型转换为 MLX 库的代码,以便在苹果设备上进行推理和微调。
“此次全面发布旨在增强和巩固开放研究社区,为未来的开放研究工作铺平道路。”苹果研究团队表示。
此外,OpenELM不使用任何全连接层中的可学习偏置参数,采用RMSNorm进行预归一化,并使用旋转位置嵌入编码位置信息。OpenELM还通过分组查询注意力代替多头注意力,用SwiGLU FFN替换了传统的前馈网络,并使用了Flash注意力来计算缩放点积注意力,能以更少的资源来进行训练和推理。同,苹果使用了动态分词和数据过滤的方法,实现了实时过滤和分词,从而简化了实验流程并提高了灵活性。还使用了与meta的Llama相同的分词器,以确保实验的一致性。
这次,苹果很有诚意将代码开源,一开到底,把所有内容都贡献出来了。仅1天多的时间,该模型GitHub平台上就获得超过1100颗星。
而目前,大模型领域主要分为开源和闭源两大阵营,国内外知名闭源的代表企业有OpenAI、Anthropic、谷歌、Midjourney、百度、出门问问等;开源阵营有meta、微软、谷歌、商汤、百川智能、零一万物等。
苹果作为手机闭源领域的*,此次却罕见地加入开源大模型阵营。有分析认为,这可能在效仿谷歌的方式先通过开源拉拢用户,再用闭源产品去实现商业化营利。
同时,这也表明苹果进军 AI 大模型领域的坚定决心。
作为同为端侧模型、开源模型企业,商汤科技联合创始人、首席科学家王晓刚近期对钛媒体App表示,开源还是对于整个社区的发展还是非常重要的,是一个重要驱动力。最终大模型的发展包括各种应用,还是要整个社区共同去推动的。对于大模型的应用也分为不同的层次,这么多行业对应用的需求也是不一样的,丰富的开源社区非常重要。
2、AI 技术持续“狂飙”,OpenAI获得了全球*块DGX H200
不止是苹果,今天凌晨,国内外 AI 技术依然“狂飙”,消息满天飞。
今晨,OpenAI联合创始人、COOGreg Brockman发推文表示,英伟达向该公司移交全球范围内*块DGX H200,此举旨在“推进人工智能、计算技术与人类的发展”。
同时,他也发布了一张合影,还包括英伟达CEO黄仁勋、OpenAI CEO奥尔特曼(Sam Altman),看起来三人非常开心。
早在2016年,OpenAI刚成立不久,黄仁勋便亲自将全球首台装备了8块英伟达P100芯片的超级计算机DGX-1送到了OpenAI的办公室。
这台价值逾百万美元的DGX-1,是黄仁勋带领英伟达3000名员工,历时三年精心打造的成果。它极大地提升了OpenAI的计算能力,将原本需要一年的训练时间缩短至仅一个月。
当时,OpenAI还处于一个初创阶段的非营利机构,这台超级计算机无疑是一份*分量的礼物。马斯克、Sam Altman以及其他早期员工对此感到无比激动,纷纷在这台DGX-1上留下了自己的签名。
2023年11月13日,英伟达发布了新一代AI GPU——NVIDIA Grace Hopper H200超级芯片,其内存容量和带宽分别是H100的两倍和1.4倍,最高支持19.5TB,AI 性能达128 petaFLOPS FP8,预计2024年第二季度开始供货。
黄仁勋称,这是拥有万亿规模的新型 AI 超级计算机,为巨型 AI 模型提供具有线性可扩展性的海量共享内存空间,能够在生成式 AI 时代发挥巨大潜力。
如今,黄仁勋亲手将全球*块DGX H200送给了OpenAI。
同时,据CTech报道,英伟达以约7亿美元收购了以色列AI基础设施编排和管理服务Run:ai,据悉,Run:ai成立于2018 年,迄今已筹集1.18亿美元,同时英伟达还收购了Deci公司。
另外,今天凌晨,拥有全球* AI 代码工程师的背后企业Cognition被曝完成了一轮1.75亿美元的融资,由Founders Fund 领投,仅仅一个月内,公司估值从3.5亿美元增长到20亿美元,引发关注。
Gartner分析师John-David Lovelock表示,随着Anthropic、OpenAI 等*梯队的玩家占据主导地位,AI投资范围正在“向外延展”(spreading out)。
“数十亿美元的投资数量已经放缓,而且几乎已经结束;热钱涌向了新方向——AI 应用。”上述分析师表示,“大模型需要大量投资,但市场现在更多地受到科技公司的影响,这些公司将利用现有的 AI 产品、服务和产品来构建新产品。”
Greylock合伙人Seth Rosenberg认为,人们对于资助AI领域的“大批新玩家”的兴趣本来就较很小。在这个周期的早期阶段,投资基础模型资本非常密集,相比之下,AI 应用和智能体所需的资本较低,这可能是*美元融资额下降的原因。
Thomvest Ventures 董事总经理 Umesh Padval 将 AI整体投资的缩减,归因于增长低于预期。他表示,最初的热情已经让位于现实—— AI 面临一部分技术挑战,一部分上市挑战,可能需要数年时间才能解决并完全克服。
”AI 投资放缓反映出人们认识到,我们仍在探索 AI 技术发展及其在各行业应用的早期阶段。虽然长期市场潜力仍然巨大,但最初的热情已被在实际应用中推广 AI 技术的复杂性和挑战所削弱……这表明投资环境更加成熟和敏锐。“Umesh Padval表示。
如今,AI 持续“狂飙”,但整个市场方向已快速转变,端侧模型、AI 应用、行业大模型等都将成为今年整个 AI 领域新趋势。